

Pada tutorial sebelumnya, saya sudah menjelaskan bagaimana cara mengambil data atau postingan terakhir dari suatu akun Twitter. Jumlah data yang diambil bisa ditentukan sendiri sesuai dengan kebutuhan asalkan kurang dari 200 tweet, sejumlah batasan yang ditetapkan oleh modul Tweepy.
Nah, bagaimana jika data postingan yang kita ambil adalah data dari akun apa pun yang mengandung kata kunci tertentu. Kemudian hasilnya nanti kita simpan ke dalam sebuah file khusus berformat .csv.
Ide dasar untuk membuat kode program tersebut yaitu dengan cara membuat sebuah objek yang memanggil class yang didalamnya berisi perintah untuk mengambil tweet, membuat dokumen bernama .csv, kemudian melakukan proses penyimpanan otomatis setiap kali ditemukan data yang mengandung kata kunci yang sudah ditentukan.
Tweepy sendiri mempunyai API khusus yang bisa dimanfaatkan untuk mengunduh twit, yaitu dengan Streaming API. API ini berguna untuk mendapatkan volume tweet yang tinggi, atau untuk membuat trigger untuk mengambil data streaming real time dari postingan pengguna. Penjelasan lebih detail mengenai penggunaan Streaming API ini bisa dibaca lebih lengkap di sini.
Proses ini akan sedikit berbeda jika dibandingkan dengan proses mengambil status twit pada tutorial ini. Pada tutorial sebelumnya, tidak diperlukan Streaming API, melainkan cukup menggunakan API user_timeline.
Berikut langkah dan penjelasan kode program Python untuk menyimpan data stream status Twitter. Tutorial berikut dijalankan menggunakan Jupyter Notebook dengan Python versi 3. Simpan kode program berikut dengan nama twitterstream.
1. Deklarasi library Tweepy, time, dan json
import tweepy from tweepy.streaming import StreamListener from tweepy import OAuthHandler from tweepy import Stream import time import json
2. Untuk mendapatkan izin penggunaan API Twitter, perlu dituliskan terlebih dahulu kode aksesnya. Kode akses ini bisa didapatkan atau request melalui tautan ini. Pada contoh berikut ganti tulisan <masukkan kode di sini> sesuai dengan kode yang Anda dapatkan dari tautan tersebut.
access_token = "<masukkan kode di sini>" access_token_secret ="<masukkan kode di sini>" consumer_key ="<masukkan kode di sini>" consumer_secret="<masukkan kode di sini>"
3. Membuat kelas Stream Listener, dengan nama ‘StdoutListener’. Kelas ini digunakan untuk menelusuri sekaligus men-download data status Twitter secara real time, kemudian menyimpan data tersebut ke dalam file .csv. Jika proses streaming gagal atau dihentikan, maka akan muncul pesan error atau ‘failed’.
class StdoutListener(StreamListener):
def on_data(self,data):
try:
data = json.loads(data)
tweet = data['text']
print(tweet)
with open('tweet.csv', 'a', encoding='utf-8') as f:
saveFile = open('gabung.csv','a')
f.write(tweet)
f.write('\n')
f.close()
return True
except BaseException as e:
print('Failed'(e))
def on_error(self,status):
print(status)
4. Pada kode di atas terdapat dua file .csv yaitu tweet.csv dan gabung.csv. Jika kode program dijalankan, kedua file tersebut otomatis akan dibuat oleh Python pada folder yang sama dengan kode program ini. File gabung.csv digunakan sebagai tempat untuk menyimpan tweet sementara, sekaligus mengganti ke dalam format encoding ‘utf-8’. Sedangkan tweet.csv merupakan file yang berisi gabungan semua tweet yang diunduh dari program Python ini.
5. Langkah selanjutnya yaitu membuat sebuah objek untuk untuk menjalankan kelas stream listener dengan izin otentikasi kode akses poin 2.
l = StdoutListener() auth = OAuthHandler(consumer_key,consumer_secret) auth.set_access_token(access_token,access_token_secret) stream = Stream(auth,l)
6. Kita bisa menambahkan filter berdasarkan kata kunci tertentu melalui fasilitas yang disediakan oleh fungsi stream.filter. Misalnya pada contoh ini saya menggunakan kata kunci ‘liverpool’. Kode yang perlu ditambahkan formatnya sebagai berikut:
stream.filter(track=['liverpool'])
7. Sekarang coba kita jalankan file tersebut, output dari program tersebut dari tampilan terminal yaitu sbb:

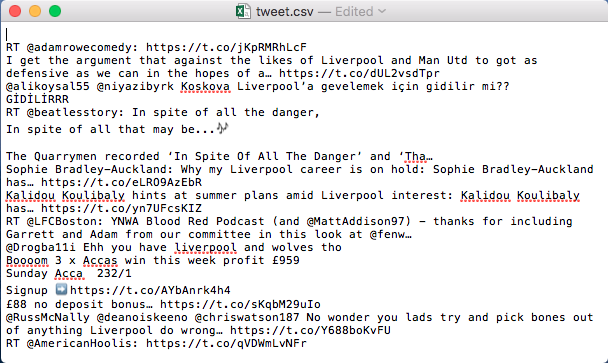
8. Kemudian amati file tweet.csv dan gabung.csv. Jika dibuka, maka isi dari gabung.csv kosong, sedangkan file tweet.csv berisi daftar kumpulan tweet yang sudah diunduh.
Jika dituliskan secara penuh, maka kode programnya sebagai berikut:
# Deklarasi library
import tweepy
from tweepy.streaming import StreamListener
from tweepy import OAuthHandler
from tweepy import Stream
import time
import json
# Inisialisasi kode akses token dan kode secret akses token
access_token = "<masukkan kode di sini>"
access_token_secret ="<masukkan kode di sini>"
consumer_key ="<masukkan kode di sini>"
consumer_secret="<masukkan kode di sini>"
# Membuat kelas stream listener
class StdoutListener(StreamListener):
def on_data(self,data):
try:
data = json.loads(data)
tweet = data['text']
print(tweet)
with open('tweet.csv', 'a', encoding='utf-8') as f:
saveFile = open('gabung.csv','a')
f.write(tweet)
f.write('\n')
f.close()
return True
except BaseException as e:
print('Failed'(e))
def on_error(self,status):
print(status)
# Membuat objek untuk untuk menjalankan kelas stream listener dengan izin otentikasi
l = StdoutListener()
auth = OAuthHandler(consumer_key,consumer_secret)
auth.set_access_token(access_token,access_token_secret)
stream = Stream(auth,l)
# Menambahkan kata kunci sebagai filter
stream.filter(track=['liverpool'])


