

Operasi tokenisasi atau tokenizing bisa dianggap sebagai tahap lanjutan dari Case Folding yang sudah pernah dibahas pada artikel sebelumnya. Tokenizing adalah operasi memisahkan teks menjadi potongan-potongan berupa token, bisa berupa potongan huruf, kata, atau kalimat, sebelum dianalisis lebih lanjut. Entitas yang bisa disebut sebagai token misalnya kata, angka, simbol, tanda baca, dan lain sebagainya.
Dengan demikian, pada tutorial tokenizing kali ini juga akan diawali dengan proses Case Folding. Ada tiga operasi yang perlu dilakukan untuk membersihkan karakter-karakter yang tidak perlu, yaitu menghapus angka, tanda baca, dan whitespace.
- Membersihkan angka. Untuk membersihkan angka diperlukan fungsi re.sub(pattern, replace_string, string). Ide dasarnya yaitu menghapus setiap karakter yang berupa angka menjadi karakter kosong “”. Misal jika ada kata “12 J4nuari” maka hasilnya menjadi “Jnuari”. Sehingga pada script Python berikut setiap karakter akan dicek dengan pattern \d+. Maksud dari pattern \d yaitu untuk mencocokkan teks dengan digit (0-9) dan pattern + berfungsi sebagai quantifier untuk menemukan 1 atau lebih karakter yang cocok dengan \d.
- Membersihkan tanda baca. Untuk membersihkan angka diperlukan fungsi .translate(). Ide dasarnya yaitu dengan mengganti karakter-karakter teks dalam string.punctuation yang mengandung (!”#$%&\’()*+,-./:;<=>?@[\\]^_`{|}~) dengan karakter kosong “”. Sehingga pada script Python berikut, fungsi .translate() akan memetakan teks ke dalam karakter yang sesuai dengan tabel pemetaan .maketrans().
- Membersihkan whitespace. Untuk membersihkan angka diperlukan fungsi .strip(). Ide dasarnya yaitu menghapus whitespace di bagian awal dan akhir teks/kalimat/kata dengan memanfaatkan fungsi regex substraction (pengurangan) yaitu re.sub(pattern, replace_string, string). Pattern yang digunakan adalah \s+, yang mana akan mencocokkan karakter dalam teks dengan quantifier 1 atau lebih whitespace.
Proses tokenizing bisa langsung menggunakan fungsi yang tersedia pada NLTK, yaitu word_tokenize(). Selain itu, untuk membantu operasi Case Folding akan digunakan library string dan regex, sehingga harus dideklarasikan di awal script.
Contoh berikut dijalankan pada Jupyter Notebook dengan Python 3.0. Kalimat yang digunakan sebagai contoh menggunakan kalimat mentah berbahasa Indonesia yang didalamnya masih mengandung karakter-karakter seperti angka, tanda baca, dan whitespace.
import nltk # Library nltk
import string # Library string
import re # Library regex
# Impor word_tokenize dari NLTK
from nltk.tokenize import word_tokenize
# Kalimat input
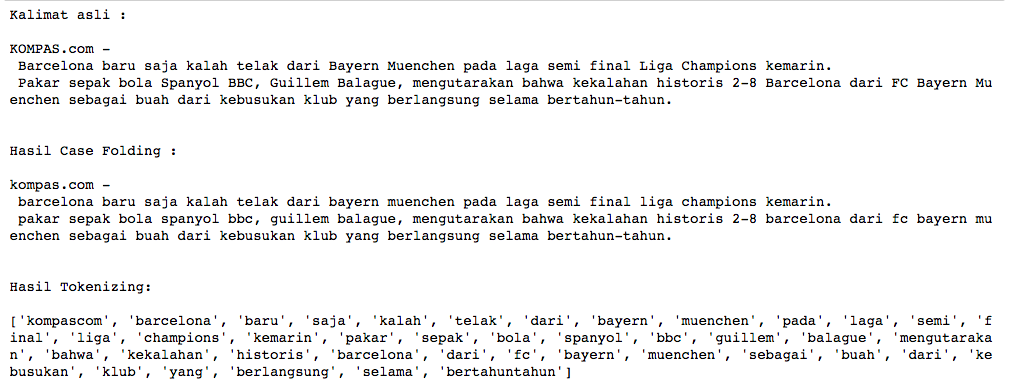
kalimat = "KOMPAS.com - \n Barcelona baru saja kalah telak dari Bayern Muenchen pada laga semi final Liga Champions kemarin. \n Pakar sepak bola Spanyol BBC, Guillem Balague, mengutarakan bahwa kekalahan historis 2-8 Barcelona dari FC Bayern Muenchen sebagai buah dari kebusukan klub yang berlangsung selama bertahun-tahun."
print('Kalimat asli : \n')
print(kalimat)
print('\n')
# ------ Operasi Case Folding --------
# Mengubah huruf kapital menjadi huruf kecil dengan fungsi .lower()
kalimat_lowercase = kalimat.lower()
print('Hasil Case Folding : \n')
print(kalimat_lowercase)
print('\n')
# Menghapus angka
kalimat_lowercase = re.sub(r"\d+", "", kalimat_lowercase)
# Menghapus tanda baca
kalimat_lowercase = kalimat_lowercase.translate(str.maketrans("","",string.punctuation))
# Menghapus whitespace
kalimat_lowercase = kalimat_lowercase.strip()
# Menghapus beberapa whitespace menjadi whitespace tunggal
kalimat_lowercase = re.sub('\s+',' ',kalimat_lowercase)
# ------ Operasi Tokenizing ---------
# ------ tokenizing per kata ---------
tokens = nltk.tokenize.word_tokenize(kalimat_lowercase)
print('Hasil Tokenizing: \n')
print(tokens)
Hasil eksekusi script di atas bisa dilihat pada tampilan berikut. Tampak perbedaan bentuk kalimat asli, bentuk setelah dilakukan case folding, dan bentuk setelah dilakukan tokenizing. Jika diperhatikan, hasil tokenizing berikut menganggap bahwa kata yang muncul lebih dari sekali akan ditampilkan sejumlah kata tersebut muncul.
Menghitung Frekuensi Kata Hasil Tokenizing
Untuk menghitung jumlah kemunculan (frekuensi) kata pada sebuah teks, kita bisa menggunakan fungsi FreqDist(). Dengan sedikit memodifikasi script di atas, kita juga bisa menampilkan outputnya ke dalam bentuk grafik. Grafik tersebut bisa disediakan melalui library pandas, sehingga perlu dideklarasikan terlebih dahulu di bagian awal script.
import nltk # Library nltk
import string # Library string
import re # Library regex
import pandas as pd # Library Panda
# Impor word_tokenize dari NLTK
from nltk.tokenize import word_tokenize
# Kalimat input
kalimat = "KOMPAS.com - \n Barcelona baru saja kalah telak dari Bayern Muenchen pada laga semi final Liga Champions kemarin. \n Pakar sepak bola Spanyol BBC, Guillem Balague, mengutarakan bahwa kekalahan historis 2-8 Barcelona dari FC Bayern Muenchen sebagai buah dari kebusukan klub yang berlangsung selama bertahun-tahun."
print('Kalimat asli : \n')
print(kalimat)
print('\n')
# ------ Operasi Case Folding --------
# Mengubah huruf kapital menjadi huruf kecil dengan fungsi .lower()
kalimat_lowercase = kalimat.lower()
print('Hasil Case Folding : \n')
print(kalimat_lowercase)
print('\n')
# Menghapus angka
kalimat_lowercase = re.sub(r"\d+", "", kalimat_lowercase)
# Menghapus tanda baca
kalimat_lowercase = kalimat_lowercase.translate(str.maketrans("","",string.punctuation))
# Menghapus whitespace
kalimat_lowercase = kalimat_lowercase.strip()
# Menghapus beberapa whitespace menjadi whitespace tunggal
kalimat_lowercase = re.sub('\s+',' ',kalimat_lowercase)
# ------ Operasi Tokenizing ---------
# ------ tokenizing per kata ---------
tokens = nltk.tokenize.word_tokenize(kalimat_lowercase)
print('Hasil Tokenizing: \n')
print(tokens)
# ------ Menghitung frekuensi kemunculan tiap kata ---------
frekuensi_tokens = nltk.FreqDist(tokens)
print('\n\nFrekuensi Tokens : \n')
print(frekuensi_tokens.most_common())
# ------ Menampilkan dalam bentuk diagram ---------
df_frekuensi_tokens = pd.DataFrame.from_dict(frekuensi_tokens, orient='index')
df_frekuensi_tokens.columns = ['Frekuensi']
df_frekuensi_tokens.index.name = 'Kata'
df_frekuensi_tokens.plot(kind='bar')
Berikut tampilan output bagian frekuensi tokens dan grafik dari script di atas:



